昨天我們認識了神經網路的基本概念包括:神經元如何接收輸入、加權求和,透過激活函數如何轉換成非線性模式並產生輸出。
一個神經元的計算會需要有輸入特徵 𝑥,然後乘上權重 𝑤(weight)加上偏置 𝑏(bias)。但這些數值是可以透過模型的學習去自動調整的哦~
所以今天我們要更進一步看看讓神經網路可以自動學習背後的演算法 反向傳播(Backpropagation),還有一起實作一個簡單的 Feedforward Neural Network!!
我們訓練模型是為了要讓模型有好的表現!但 「好表現」具體來說是什麼意思?
模型主要的任務是要做預測,那我們就是希望模型「預測的結果」和「真實結果」的差距越小越好。所以有一個概念叫做 「損失」(Loss) 指得就是模型預測和真實標籤之間的差距。而我們的目標就是要 「最小化損失」。
整個流程可以分為以下五個步驟:
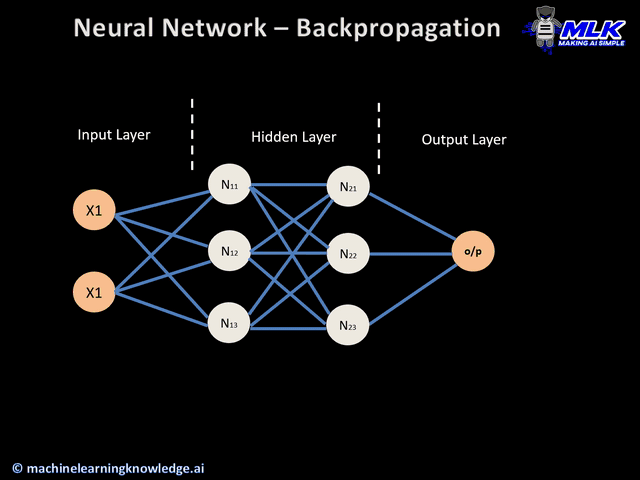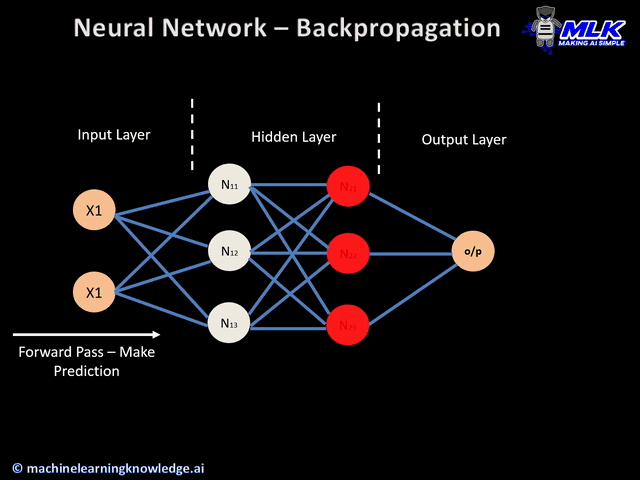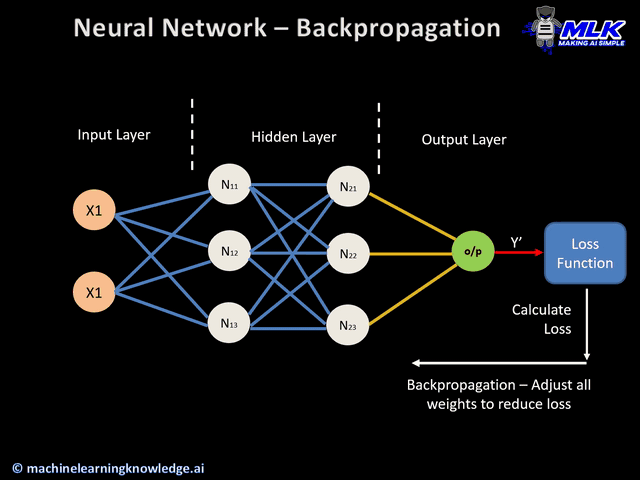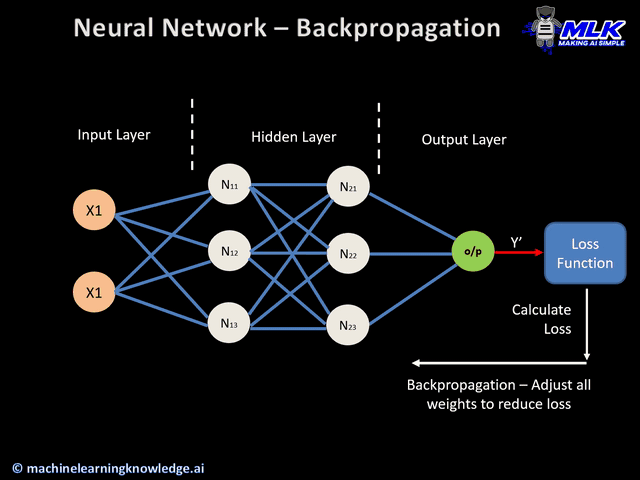
圖片來源:https://medium.com/analytics-vidhya/backpropagation-for-dummies-e069410fa585
那我們來介紹以下四個核心概念:
前向傳播就是用以上這個公式先計算出一個數值 𝑦
用損失函數(Loss Function)計算出預測值 𝑦 跟真實值的差距。
損失函數有很多種,在分類任務中常用的是 交叉熵(Cross-Entropy Loss)。
利用 鏈式法則(Chain Rule) 計算每個權重對損失的影響,再將誤差從輸出層往後傳回到輸入層。
利用損失函數的「斜率」來決定怎麼調整權重。也會透過設定學習率 𝜂 來控制每次更新的步伐。可以想像我們在一座山坡上(損失函數),要往山谷(最佳解)走。梯度就像坡度,學習率(Learning Rate)就像走路的步伐大小。
這段程式實作一樣會使用 kaggle 的 IMDb 50K Cleaned Movie Reviews 資料集。然後會用 Word2Vec 轉成 embedding 之後,再用 PyTorch 建置一個簡單的前饋神經網路。
1. 讀取資料
import kagglehub
import os
import pandas as pd
path = kagglehub.dataset_download("ibrahimqasimi/imdb-50k-cleaned-movie-reviews")
csv_path = os.path.join(path, "IMDB_cleaned.csv")
df = pd.read_csv(csv_path)
2. 資料前處理
import torch
from gensim.models import Word2Vec
# 將句子拆成單詞轉成 embedding
sentences = [review.split() for review in df['cleaned_review']]
w2v_model = Word2Vec(sentences, vector_size=50, window=5, min_count=1, workers=4)
# 將每篇文章的單詞向量平均
def embed_sentence(sentence):
vecs = [w2v_model.wv[word] for word in sentence if word in w2v_model.wv]
if len(vecs) == 0:
return torch.zeros(50)
return torch.tensor(vecs).mean(dim=0)
# feature
X = torch.stack([embed_sentence(s.split()) for s in df['cleaned_review']])
# label
y = torch.tensor([1 if s=='positive' else 0 for s in df['sentiment']], dtype=torch.float32)
3. 切分資料集&將資料裝成 Data Loader
使用 DataLoader 可以:
from torch.utils.data import DataLoader, TensorDataset
# training set:test set => 8:2
train_size = int(0.8 * len(X))
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# 建立 Tensor Dataset
train_ds = TensorDataset(X_train, y_train)
test_ds = TensorDataset(X_test, y_test)
# 建立 Data Loader
train_loader = DataLoader(train_ds, batch_size=64, shuffle=True)
test_loader = DataLoader(test_ds, batch_size=64)
4. 建立模型
input_dim:資料轉成向量是 50 維hidden_dim:自訂隱藏層維度 32 維output_dim:二元分類所以是 1 個值fc1:輸入層 → 隱藏層,維度 [50 → 32]。relu:隱藏層激活函數。fc2:隱藏層 → 輸出層,輸出 1 個值。sigmoid:輸出層激活函數,將結果壓縮到 [0, 1],適合二元分類。forward():把輸入 x 依序經過 隱藏層 → 激活函數 → 輸出層 → Sigmoid
import torch.nn as nn
import torch.optim as optim
class SimpleMLP(nn.Module):
def __init__(self, input_dim=50, hidden_dim=32, output_dim=1):
super().__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, output_dim)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.sigmoid(self.fc2(x))
return x.squeeze()
model = SimpleMLP()
criterion = nn.BCELoss() # 損失函數
optimizer = optim.Adam(model.parameters(), lr=0.001) # 優化器、學習率
5. 訓練模型
model.train()
epochs = 5
for epoch in range(epochs):
model.train()
total_loss = 0
for xb, yb in train_loader: # 批次訓練
optimizer.zero_grad() # 每次訓練梯度歸零
preds = model(xb) # 前向傳播
loss = criterion(preds, yb) # 計算損失
loss.backward() # 反向傳播
optimizer.step() # 更新權重
total_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {total_loss/len(train_loader):.4f}")
# === Output ===
Epoch 1/5, Loss: 0.6847
Epoch 2/5, Loss: 0.6729
Epoch 3/5, Loss: 0.6620
Epoch 4/5, Loss: 0.6553
Epoch 5/5, Loss: 0.6460
6. 評估模型
model.eval()
from sklearn.metrics import precision_score, recall_score, f1_score
y_true = []
y_pred = []
model.eval()
with torch.no_grad(): # 關閉梯度計算
for xb, yb in test_loader:
outputs = model(xb)
preds = (outputs >= 0.5).float()
y_true.extend(yb.cpu().numpy())
y_pred.extend(preds.cpu().numpy())
# 計算 metrics
acc = sum([1 if p == t else 0 for p, t in zip(y_pred, y_true)]) / len(y_true)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"Accuracy : {acc:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall : {recall:.4f}")
print(f"F1-score : {f1:.4f}")
# === Output ===
Accuracy : 0.6600
Precision: 0.7208
Recall : 0.5111
F1-score : 0.5981
今天我們更深入的了解了模型到底是怎麼做到「自己學習」這件事,是透過 前向傳播 → 計算損失 → 反向傳播 → 梯度下降 的步驟去調整權重,慢慢讓損失下降~
最後也實作了一個簡單的前饋神經網路。雖然這個模型已經可以對每篇文章做分類,但它其實有一個缺點!就是它完全忽略文字的 順序性。它看到的只是「一袋詞」的平均特徵,而無法理解文字的脈絡或語句的前後關係。
所以接下來我們會進入 「序列模型」 的世界,從 RNN 開始,學會如何讓模型「記住長長的故事」,再進一步用 LSTM 處理長短期依賴問題,讓模型更能具備像人一樣的 「記憶力」!!

